Lighthouse LabsW1D5 - Organizing DataInstructor: Socorro E. Dominguez-Vidana |

|

|
Name: Socorro Dominguez-Vidana Work: University of Wisconsin-Madison Data Scientist Hobbies: Kung Fu, traveling, learning languages |
Overview¶
- [] Importance of Organizing Data
- [] Unions
- [] Views
- [] Temporary Tables
- [] CTEs
- [] Best practices
Follow with ![]()
%load_ext sql
%sql postgresql://sedv8808@localhost/insurance
Importance of Organizing Data¶
- To make code more understandable for yourself and for others.
- To improve readability and maintainability.
- To help in error handling and debugging.

Work Chronicles. (n.d.). Workplace comics and humor. Retrieved January 6, 2025
What is Organized Data¶
Organized Data has the following properties:
Structured Format: Data is stored in a predefined format, such as rows and columns in a spreadsheet or database table.
Logical Grouping: Data is categorized into logical groups (e.g., by date, category, department, or region).
Consistency: Data follows consistent conventions for formatting, such as dates in a uniform format (e.g., YYYY-MM-DD), standardized names, or units of measurement.
Labeled and Descriptive: Each data point is clearly labeled or associated with metadata, making its purpose or context understandable (e.g. headers like Name, Date, etc).
Easily Queryable or Analyzable: Organized data is stored in a way that allows for efficient querying, filtering, and analysis using tools or programming languages.
UNIONs¶
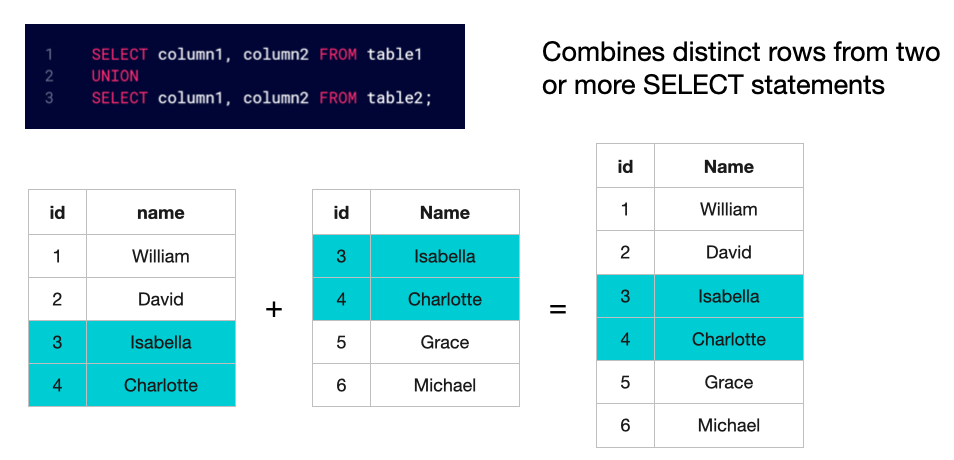
- A
UNIONoperator is used to combine the results of two or moreSELECTstatements into a single result set. The result contains rows from allSELECTqueries, stacked vertically.
Types of UNIONs:
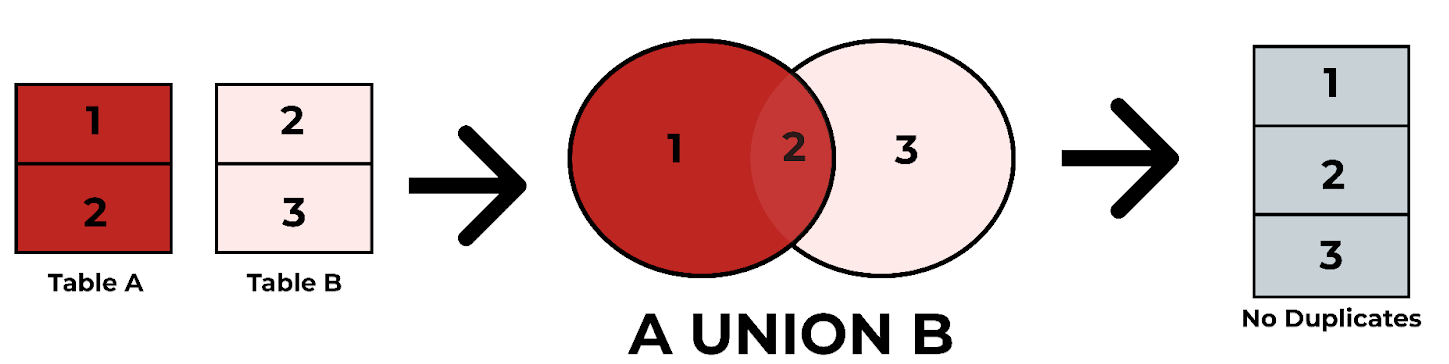
UNION: - Combines the result sets of two or more queries and removes duplicate rows from the final output. - Use when you want unique results from multiple queries. - Example:
SELECT name FROM employees
UNION
SELECT name FROM managers;
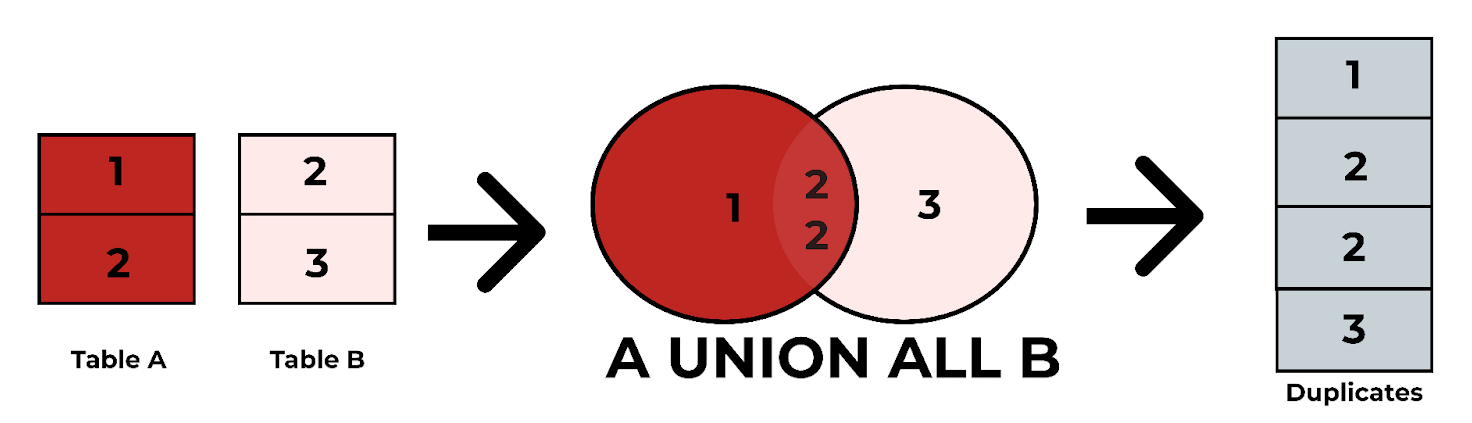
UNION ALL:- Combines the result sets of two or more queries but keeps duplicate rows in the output.
- Use when performance is critical or when duplicates are expected and meaningful.
- Example:
SELECT name FROM employees
UNION ALL
SELECT name FROM managers;
Case Study¶
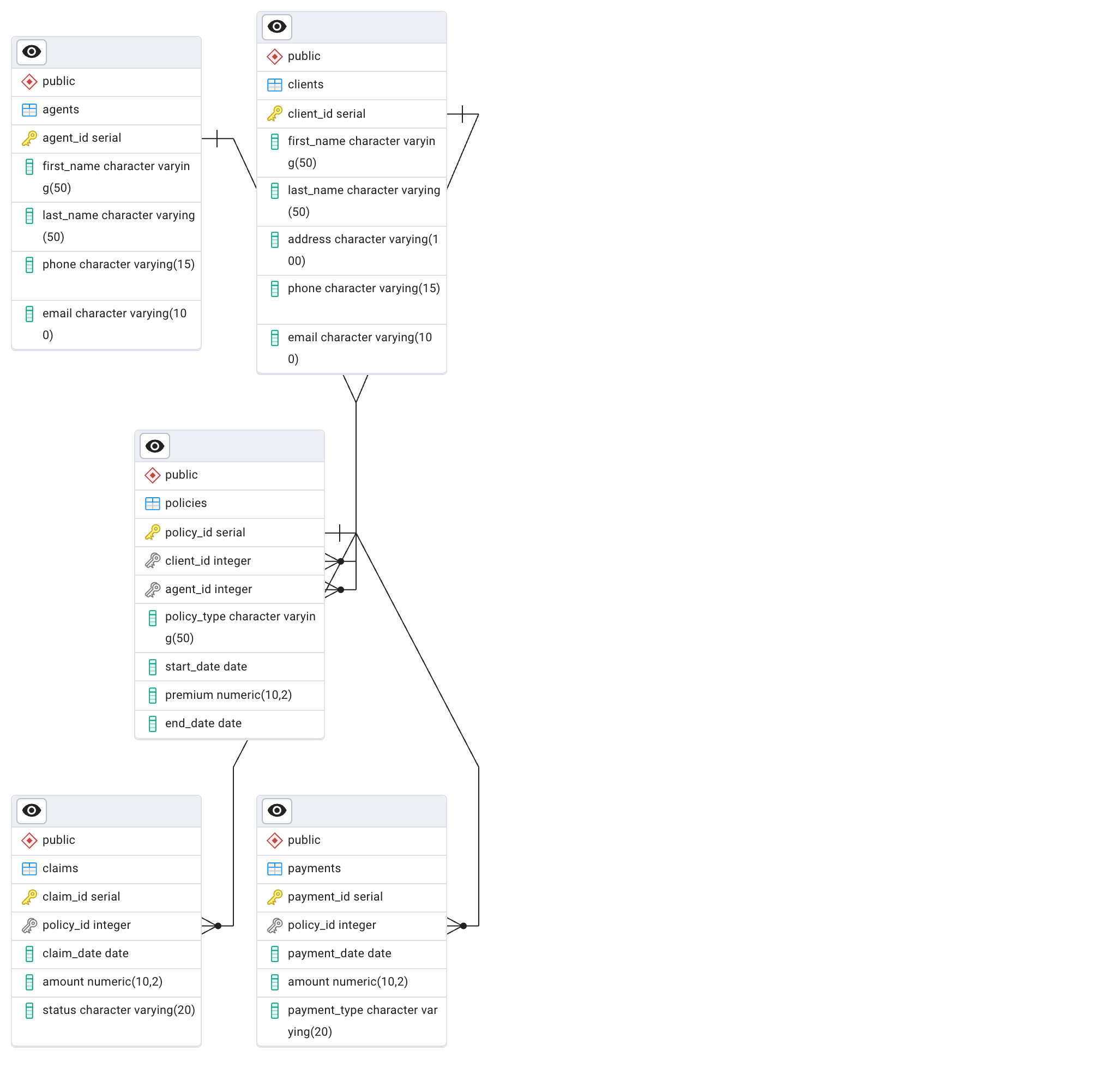
This Binder has an insurance database that simulates a fictional insurance company, HT-Insurance, and contains essential information about clients, policies, claims, agents, and payments.
We are going to follow Emma, an actuarial analyst in HT-Insurance and do some insurance-related activities, such as evaluating claims, tracking policy information, and analyzing payments.
Database Tables and Relationships:¶
- Clients: This table stores basic information about each client, such as their name, address, and contact details.
- Agents: This table contains details about the insurance agents who manage policies for clients.
- Policies: This table tracks the insurance policies taken out by clients, including details about policy type, premium, and the agent managing the policy.
- Claims: This table stores data about claims filed by clients on their policies, including the amount of the claim and its current status.
- Payments: This table records payments made by clients toward their policies, including the amount and the type of payment.
%%sql
SELECT CONCAT(first_name, ' ', last_name) AS person_name
FROM Clients
UNION
SELECT CONCAT(first_name, ' ', last_name) AS person_name
FROM Agents
LIMIT 5;
* postgresql://sedv8808@localhost/insurance 5 rows affected.
| person_name |
|---|
| James Johnson |
| Ava Allen |
| Ethan Lopez |
| Mia Rivera |
| Lucas Robinson |
Listing All (Repeated) Clients and Agents¶
%%sql
SELECT CONCAT(first_name, ' ', last_name) AS person_name
FROM Clients
UNION ALL
SELECT CONCAT(first_name, ' ', last_name) AS person_name
FROM Agents
ORDER BY person_name DESC
LIMIT 5;
* postgresql://sedv8808@localhost/insurance 5 rows affected.
| person_name |
|---|
| William Hughes |
| Sophia Wright |
| Sophia Martinez |
| Sarah Wilson |
| Robert Brown |
- Combines rows from Clients and Agents tables, aligning
client_idwithagent_idandclient_namewithagent_name. UNION ALLretains all rows even if they are duplicated.
Comparing Counts Across Tables¶
%%sql
SELECT 'Clients'
AS table_name,
COUNT(*) AS count_rows,
COUNT(DISTINCT(client_id)) AS count_distinct
FROM Clients
UNION ALL
SELECT 'Policies'
AS table_name,
COUNT(*) AS count_rows,
COUNT(DISTINCT(policy_type)) AS count_distinct
FROM Policies
UNION ALL
SELECT 'Claims'
AS table_name,
COUNT(*) AS count_rows,
COUNT(DISTINCT(status)) AS count_distinct
FROM Claims;
* postgresql://sedv8808@localhost/insurance 3 rows affected.
| table_name | count_rows | count_distinct |
|---|---|---|
| Clients | 30 | 30 |
| Policies | 12 | 4 |
| Claims | 8 | 3 |
Combining Financial Transactions by Policy Type (Payments and Claims)¶
%%sql
SELECT
pol.policy_type,
SUM(pa.amount) AS total_amount,
'Policy Payments'
AS transaction_source
FROM policies pol
JOIN payments pa
ON pa.policy_id = pol.policy_id
GROUP BY pol.policy_type
UNION ALL
SELECT
pol.policy_type,
SUM(cl.amount) AS total_amount,
'Claim Settlements'
AS transaction_source
FROM claims cl
JOIN policies pol
ON cl.policy_id = pol.policy_id
GROUP BY policy_type;
* postgresql://sedv8808@localhost/insurance 8 rows affected.
| policy_type | total_amount | transaction_source |
|---|---|---|
| Life | 700.00 | Policy Payments |
| Health | 700.00 | Policy Payments |
| Auto | 1500.00 | Policy Payments |
| Home | 2200.00 | Policy Payments |
| Life | 4500.00 | Claim Settlements |
| Health | 2000.00 | Claim Settlements |
| Auto | 7200.00 | Claim Settlements |
| Home | 6800.00 | Claim Settlements |
- Calculates the total payment amounts and total settled claim amounts per policy type.
- Combines these into a single result using
UNION ALL. - Keeps payments and claim data distinct by including
transaction_source.
High-Value Transactions¶
%%sql
SELECT
policy_id,
amount AS transaction_amount,
'High Payment'
AS transaction_type
FROM payments
WHERE amount > 1000
UNION
SELECT
policy_id,
amount AS transaction_amount,
'High Claim'
AS transaction_type
FROM claims
WHERE amount > 1000 AND status = 'Settled';
* postgresql://sedv8808@localhost/insurance 1 rows affected.
| policy_id | transaction_amount | transaction_type |
|---|---|---|
| 6 | 1200.00 | High Payment |
- Combines high-value payments and high-value settled claims into one result set.
When to use UNION¶
- Combining data from multiple tables
- Merging data from multiple queries
- Aggregating data from different sources
- Same number of columns with compatible data types (column names can be different)

VIEWs¶
Views are "Virtual" tables.
- Based on Queries: A view is created by defining a SQL query that pulls data from one or more tables.
- Make data more consistent
- Improve performance
- Are typically read-only, but in some cases, they can be updated if they meet certain conditions.
- Enhance security: Views can restrict access to specific columns or rows, exposing only the required data.
SELECT * FROM my_view
Creating a View¶
CREATE VIEW view_name AS
SELECT column1, column2, ...
FROM table_name
WHERE condition;
%%sql
CREATE VIEW MonthlyPayments AS
SELECT payment_id, policy_id, amount
FROM payments
WHERE payment_type = 'Monthly';
* postgresql://sedv8808@localhost/insurance Done.
[]
Using a View¶
%%sql
SELECT * FROM MonthlyPayments;
* postgresql://sedv8808@localhost/insurance 1 rows affected.
| payment_id | policy_id | amount |
|---|---|---|
| 3 | 3 | 300.00 |
Modifying a View¶
You can update a view's definition using the CREATE OR REPLACE VIEW statement:
%%sql
CREATE OR REPLACE VIEW MonthlyPayments AS
SELECT payment_id, policy_id, amount, payment_type
FROM payments
WHERE payment_type = 'Monthly';
* postgresql://sedv8808@localhost/insurance Done.
[]
Deleting a View¶
You can delete a View the same way you can drop a table.
%%sql
DROP VIEW IF EXISTS MonthlyPayments;
* postgresql://sedv8808@localhost/insurance Done.
[]
Limitations of Views¶
- Performance Overhead: Since views are recalculated on each access, they may impact performance for complex or large queries.
- Read-Only: Some views cannot be updated or inserted into if they are based on complex queries or use joins and aggregations.
- Dependency Issues: Dropping or altering underlying tables can break a view.
Types of Views¶
- Simple Views:
- Based on a single table and do not use functions, joins, or groupings.
- Usually updatable.
- Complex Views:
- Based on multiple tables and can include joins, subqueries, and aggregation.
- Often read-only.
- Materialized Views:
- Unlike regular views, materialized views store the query result physically, improving performance for frequent access.
For a Materialized View, the command is:
CREATE MATERIALIZED VIEW MonthlyPayments AS
SELECT payment_id, policy_id, amount
FROM payments
WHERE payment_type = 'Monthly';
Temporary Tables¶
Tables that exist only in a specific "session".
- Store data temporarily for intermediate calculations or processing.
- Particularly useful for breaking down complex queries.
- Temporary tables are automatically dropped at the end of the session or transaction, depending on their scope.
- To create a
Temporary Table:
CREATE TEMP TABLE t_temp_test AS
SELECT * FROM my_table
%%sql
CREATE TEMPORARY TABLE HighValueClaims AS
SELECT claim_id, policy_id, amount
FROM Claims
WHERE amount > 1000;
* postgresql://sedv8808@localhost/insurance 7 rows affected.
[]
- To use it:
SELECT * FROM t_temp_test
%%sql
SELECT * FROM HighValueClaims
* postgresql://sedv8808@localhost/insurance 7 rows affected.
| claim_id | policy_id | amount |
|---|---|---|
| 1 | 1 | 2000.00 |
| 2 | 2 | 5000.00 |
| 3 | 3 | 1500.00 |
| 4 | 4 | 3000.00 |
| 5 | 5 | 4500.00 |
| 6 | 6 | 1800.00 |
| 8 | 8 | 2200.00 |
- To delete it:
DROP TABLE IF EXISTS t_temp_test
%%sql
DROP TABLE HighValueClaims;
* postgresql://sedv8808@localhost/insurance Done.
[]
Common Table Expressions (CTEs)¶
Common Table Expressions are a temporary, named result set that is defined within a SQL query.
It simplifies complex queries by breaking them into smaller, readable parts.
- Temporary Scope:
- The CTE exists only during the execution of the
SQLstatement. - It is not stored in the database.
- Improved Readability:
- CTEs make complex queries easier to read and maintain by structuring them into logical sections.
- Reusable in a Query:
- A CTE can be referenced multiple times within the same query, reducing repetition.
Defining CTEs¶
WITH cte_name AS (
SELECT column1, column2
FROM table_name
WHERE condition
)
SELECT *
FROM cte_name;
Example: Find clients who have paid more than $1,000 in total.
%%sql
WITH TotalPayments AS (
SELECT
pol.client_id,
SUM(pay.amount) AS total_paid
FROM payments pay
JOIN policies pol ON pay.policy_id = pol.policy_id
GROUP BY pol.client_id
)
SELECT
cl.client_id,
CONCAT(cl.first_name, ' ', cl.last_name) AS client_name,
tp.total_paid
FROM TotalPayments tp
JOIN clients cl ON tp.client_id = cl.client_id
WHERE tp.total_paid > 1000;
* postgresql://sedv8808@localhost/insurance 1 rows affected.
| client_id | client_name | total_paid |
|---|---|---|
| 6 | Sarah Wilson | 1200.00 |
Why this works?
- The CTE calculates the total payments
(SUM(pay.amount))made for eachclient_id. - It links the payments table to the policies table using the
policy_idcolumn. - The
GROUP BY pol.client_idensures we aggregate payments for each uniqueclient_id.
How the CTE works:
- The
JOINcombines the payments table and policies table using the common columnpolicy_id. This allows us to find out whichclient_idis associated with each payment. SUM: For eachclient_id, the query sums up the amount column from the payments table.GROUP BY: Ensures the aggregation (SUM) happens at theclient_idlevel, giving one row per client.
The result of the CTE (TotalPayments) is a table that looks something like this:
%%sql
SELECT pol.client_id,
SUM(pay.amount) AS total_paid
FROM payments pay
JOIN policies pol ON pay.policy_id = pol.policy_id
GROUP BY pol.client_id;
* postgresql://sedv8808@localhost/insurance 8 rows affected.
| client_id | total_paid |
|---|---|
| 3 | 300.00 |
| 5 | 700.00 |
| 4 | 550.00 |
| 6 | 1200.00 |
| 2 | 1000.00 |
| 7 | 400.00 |
| 1 | 500.00 |
| 8 | 450.00 |
The main query:
SELECT
cl.client_id,
CONCAT(cl.first_name, ' ', cl.last_name) AS client_name,
tp.total_paid
FROM TotalPayments tp
JOIN clients cl ON tp.client_id = cl.client_id
WHERE tp.total_paid > 1000;
TotalPayments is joined with the clients table on the client_id column.
- This allows us to add client details (
first_nameandlast_name) to the total payment data.
This query works because:
- It separates the logic into a reusable CTE (TotalPayments) to calculate total payments for each client.
- It joins the CTE with the clients table to include client details.
- It filters aggregated results using
WHEREafter the aggregation is done in the CTE.
Challenge Time¶
- Create a view called
policy_summarythat summarizes the total premium paid for each policy type. Include columns forpolicy_type,total_policies, andtotal_premium.
- Write a query that uses a CTE to calculate:
- The total number of claims per policy type.
- The total amount of claim settlements (from claims) per policy type where the status is 'Settled'.
- Use the CTE result to generate a final output of
policy_type,total_claims, andtotal_claim_amount.
- Create a temporary table that stores:
- All clients who have active policies (i.e.,
end_dateis in the future). - Write a query using this temporary table to get the list of clients with their policies, ordered by the policy end date.
- Write a query that:
- Retrieves all policy payments (from payments) and claim settlements (from claims where status is 'Settled').
- Use UNION for policy payments and claim settlements where the amounts are the same.
- Use UNION ALL for all other records.